目录
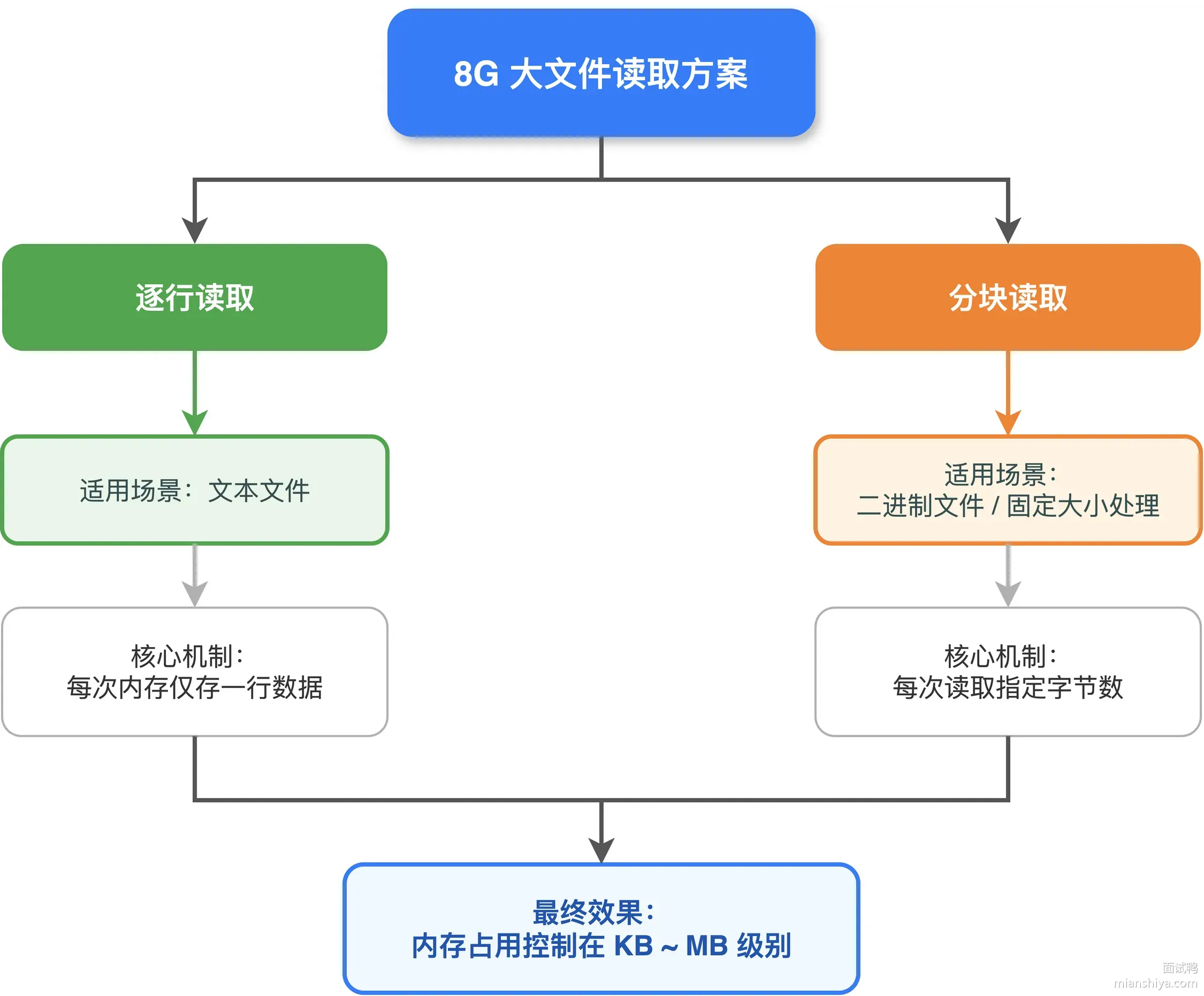
核心思路就是分而治之,不要把整个文件一股脑儿塞进内存,而是一点一点地读、一点一点地处理。
Python 提供了两种主流方案:逐行读取和分块读取。
- 逐行读取适合文本文件,每次只在内存里放一行数据
- 分块读取适合二进制文件或需要固定大小处理的场景,每次读指定字节数。
两种方式都能把 8G 文件的内存占用压到几 KB 到几 MB 级别。
逐行读取
直接用 for 循环遍历文件对象就行,Python 底层会自动帮你一行一行地读,内存里永远只有当前这一行:
Pythonwith open('large_file.txt', 'r') as file:
for line in file:
process(line)
这种写法比显式调用 readline() 更 Pythonic,底层走的是文件对象的迭代器协议,每次 next 读一行进缓冲区。
分块读取
处理二进制文件或者需要按固定块大小处理时,用 read(size) 配合生成器:
Pythondef read_in_chunks(file_object, chunk_size=1024 * 1024): # 1MB 一块
while True:
data = file_object.read(chunk_size)
if not data:
break
yield data
with open('large_file.dat', 'rb') as file:
for chunk in read_in_chunks(file):
process(chunk)
chunk_size 怎么定?一般设 1MB 到 64MB,太小了 IO 次数多,太大了内存占用高。实际项目里可以根据磁盘类型调整,SSD 上 4MB 到 16MB 比较合适,机械硬盘上大一点能减少寻道开销。
mmap 内存映射
mmap 是另一个处理大文件的利器。它把文件直接映射到进程的虚拟地址空间,读写文件就像操作内存数组一样,操作系统会自动处理缺页中断和磁盘 IO。
Pythonimport mmap
with open('large_file.txt', 'r+b') as f:
with mmap.mmap(f.fileno(), 0) as mm:
# 像操作字节数组一样操作文件
print(mm[:100]) # 读前 100 字节
mm[0:5] = b'Hello' # 直接修改文件内容
mmap 的好处是支持随机访问,比如你想读文件中间某一段,不用从头遍历。它还能利用操作系统的页面缓存,多次访问同一位置时性能很好。
传统读文件要经过两次拷贝:磁盘到内核缓冲区,内核缓冲区到用户空间。mmap 直接把文件映射到用户空间的虚拟内存,访问时触发缺页中断,操作系统把对应的页从磁盘加载到物理内存,省掉了一次拷贝。
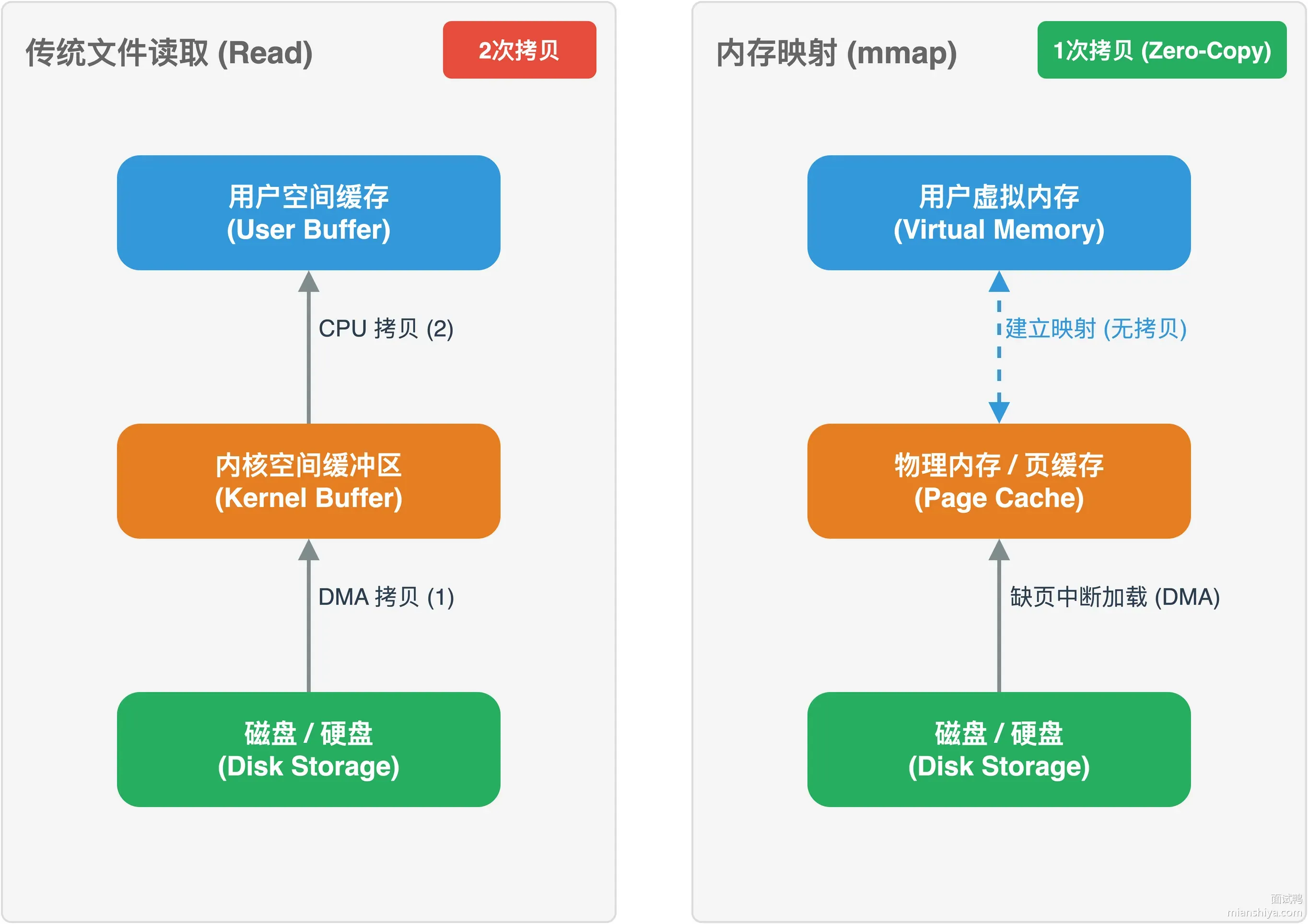
不过 mmap 也有坑:
1)映射超大文件时,32 位系统的虚拟地址空间只有 4GB,映射 8GB 文件会失败。64 位系统没这个问题。
2)映射文件后修改内容,如果程序异常退出,可能导致文件损坏。
3)mmap 不适合顺序读取整个文件的场景,这种情况普通的分块读取反而更快,因为 mmap 有缺页中断的开销。
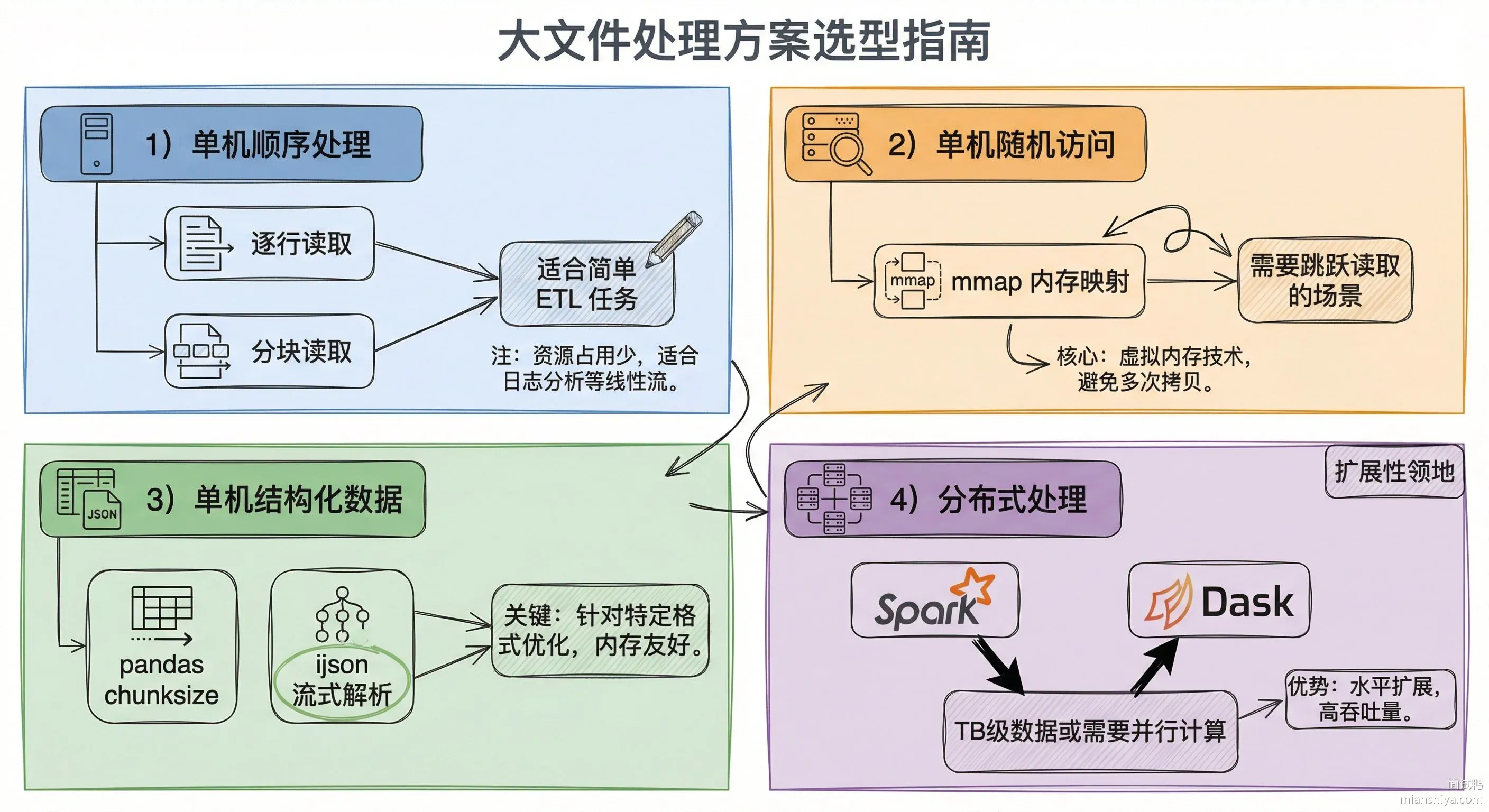
针对特定格式的优化
处理 CSV、JSON、日志这类结构化数据时,有更高效的库:
Python# pandas 分块读 CSV
import pandas as pd
for chunk in pd.read_csv('huge.csv', chunksize=100000):
process(chunk)
# ijson 流式解析 JSON
import ijson
with open('huge.json', 'rb') as f:
for item in ijson.items(f, 'item'):
process(item)
pandas 的 chunksize 参数让它变成一个分块迭代器,每次返回指定行数的 DataFrame。ijson 是流式 JSON 解析器,不会把整个 JSON 加载到内存,适合处理几个 GB 的 JSON 文件。
分布式处理
文件大到单机处理不动时,就得上分布式了。Spark 的 RDD 天然支持大文件分片处理:
Pythonfrom pyspark import SparkContext
sc = SparkContext()
rdd = sc.textFile('hdfs://path/to/huge_file.txt')
result = rdd.map(process_line).reduce(aggregate)
Spark 会自动把文件按 HDFS 的 block 大小切分成多个分区,分发到集群各节点并行处理。一个 8GB 的文件,4 台机器同时处理,理论上能快 4 倍。
内存监控和调优
跑大文件处理任务时,盯着内存占用很重要。可以用 memory_profiler 来分析:
Pythonfrom memory_profiler import profile
@profile
def process_large_file(filename):
with open(filename, 'r') as f:
for line in f:
process(line)
如果发现内存持续增长,多半是处理逻辑里有东西没释放干净,比如把结果都 append 到一个列表里了。这时候要么改成流式输出,要么手动 del 加 gc.collect()。
本文作者:Dewar
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!