目录
Python 实现多线程主要靠 threading 模块。最常用的两种方式:一是直接给 threading.Thread 传一个 target 函数,二是继承 Thread 类然后重写 run 方法。
Pythonimport threading
import time
def print_numbers():
for i in range(5):
print(f'Number: {i}')
time.sleep(1)
def print_letters():
for letter in 'abcde':
print(f'Letter: {letter}')
time.sleep(1)
# 创建线程
thread1 = threading.Thread(target=print_numbers)
thread2 = threading.Thread(target=print_letters)
# 启动线程
thread1.start()
thread2.start()
# 等待线程结束
thread1.join()
thread2.join()
print('Done.')
上面这段代码创建了两个线程分别跑 print_numbers 和 print_letters。调用 start() 让线程开始执行,join() 则是让主线程等着子线程跑完再继续往下走。
线程的生命周期大致是:创建线程对象 → 调用 start() 进入就绪状态 → 获取 CPU 时间片开始执行 → 执行完毕或遇到 join() 等待 → 线程结束

GIL 的影响
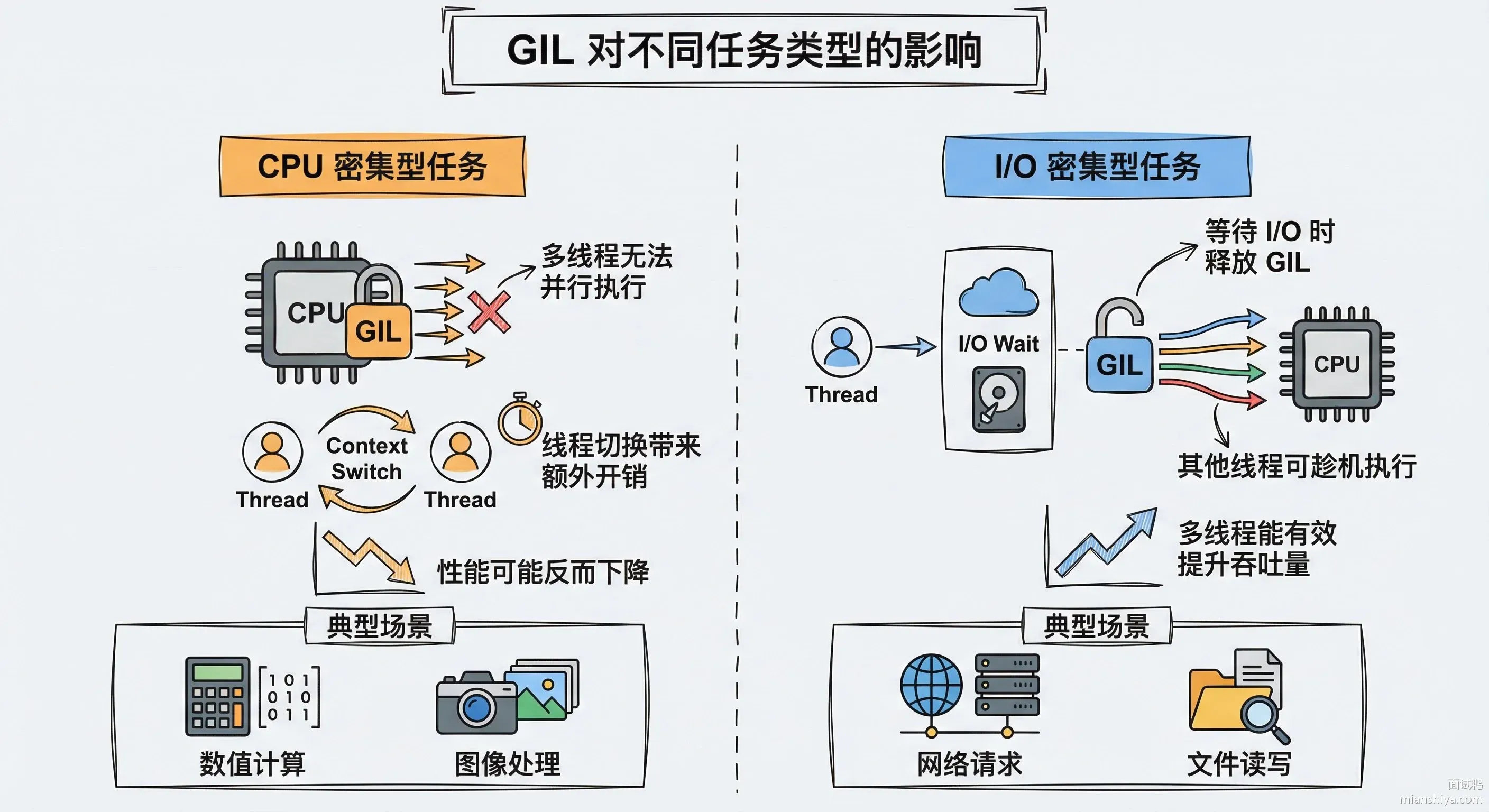
Python 有个东西叫 GIL,全局解释器锁。这玩意儿规定了同一时刻只能有一个线程执行 Python 字节码,哪怕你开了 8 个线程,底层也是轮流跑。所以跑 CPU 密集型任务的时候,多线程根本提升不了性能,8 个线程可能还不如单线程快,因为还有线程切换开销。
但如果你的任务是 I/O 密集型的,比如爬虫、读写文件、调接口,那多线程还是很有用的。因为等网络响应的时候线程会释放 GIL,其他线程就能趁机干活。
多进程绕过 GIL
如果真想并行跑 CPU 密集型任务,得用 multiprocessing 模块。每个进程有自己独立的 Python 解释器和 GIL,互不干扰。比如你有个 8 核的机器,开 8 个进程就能把 CPU 吃满。
Pythonfrom multiprocessing import Process
import time
def print_numbers():
for i in range(5):
print(f'Number: {i}')
time.sleep(1)
def print_letters():
for letter in 'abcde':
print(f'Letter: {letter}')
time.sleep(1)
# 创建进程
process1 = Process(target=print_numbers)
process2 = Process(target=print_letters)
# 启动进程
process1.start()
process2.start()
# 等待进程结束
process1.join()
process2.join()
print('Done.')
代价就是进程间通信比线程麻烦,得用 Queue、Pipe 或者共享内存,数据要序列化传输,开销比线程大不少。
异步编程
对于 I/O 密集型任务,还有另一条路:用 asyncio 做异步编程。Python 3.5 之后引入了 async/await 语法,写起来比回调舒服多了。异步是单线程的,靠事件循环调度协程,没有线程切换开销,几万个并发连接用一个线程就能扛住。
Pythonimport asyncio
async def print_numbers():
for i in range(5):
print(f'Number: {i}')
await asyncio.sleep(1)
async def print_letters():
for letter in 'abcde':
print(f'Letter: {letter}')
await asyncio.sleep(1)
async def main():
await asyncio.gather(print_numbers(), print_letters())
asyncio.run(main())
print('Done.')
线程池
如果要管理一堆线程,手动 start/join 太累了。concurrent.futures.ThreadPoolExecutor 提供了线程池,帮你复用线程、控制并发数、收集结果。
Pythonfrom concurrent.futures import ThreadPoolExecutor
import time
def print_numbers():
for i in range(5):
print(f'Number: {i}')
time.sleep(1)
def print_letters():
for letter in 'abcde':
print(f'Letter: {letter}')
time.sleep(1)
with ThreadPoolExecutor(max_workers=2) as executor:
executor.submit(print_numbers)
executor.submit(print_letters)
print('Done.')
线程池的好处是线程可以复用,不用每次任务都新建销毁,对于需要频繁执行短任务的场景特别合适。一般 max_workers 设成 CPU 核心数的 2-4 倍就差不多了。
本文作者:Dewar
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!